

Kredyty obrazkowe: Google
Nadążanie za szybko rozwijającą się branżą, taką jak sztuczna inteligencja, to trudne zadanie. Aby sztuczna inteligencja zrobiła to za Ciebie, oto przydatne podsumowanie wydarzeń ze świata uczenia maszynowego z zeszłego tygodnia, wraz z godnymi uwagi badaniami i eksperymentami, których nie omówilibyśmy sami.
W tym tygodniu Google zdominowało cykl wiadomości o sztucznej inteligencji dzięki garstce nowych produktów wprowadzonych na doroczną konferencję programistów I / O. Obejmują gamę od sztucznej inteligencji do generowania kodu, która ma konkurować z Copilot GitHub, do generatora muzyki AI, który jest Turns podpowiedzi tekstowe do krótkich piosenek.
Sporo z tych narzędzi wydaje się być uzasadnionymi oszczędzaczami siły roboczej – to znaczy więcej marketingowego puchu. Szczególnie intryguje mnie Project Tailwind, aplikacja do robienia notatek, która wykorzystuje sztuczną inteligencję do organizowania, podsumowywania i analizowania plików z mojego osobistego folderu Dokumentów Google. Ujawniają jednak również ograniczenia i wady nawet najlepszych współczesnych technologii sztucznej inteligencji.
Weźmy na przykład PaLM 2, najnowszy duży model językowy Google (LLM). PaLM 2 będzie zasilać zaktualizowane narzędzie Google do czatu Bard, konkurenta firmy dla ChatGPT OpenAI, i służyć jako model podstawowy dla większości nowych funkcji AI Google. Ale chociaż PaLM 2 może pisać kod, wiadomości e-mail i nie tylko, podobnie jak porównywalne LLM, odpowiada również na pytania w toksyczny i stronniczy sposób.
Google Music Generator również ma nieco ograniczone możliwości. Jak pisałem własnoręcznie, większość utworów, które stworzyłem za pomocą MusicLM brzmi w najlepszym razie znośnie – aw najgorszym jak czterolatek wydany KAWKA.
Wiele napisano o tym, jak sztuczna inteligencja zastąpi miejsca pracy – potencjalnie równowartość 300 milionów pełnoetatowych miejsc pracy, według raport przez Goldmana Sachsa. W rekonesans Zdaniem Harrisa, 40% pracowników zaznajomionych z opartym na sztucznej inteligencji narzędziem chatbota OpenAI, ChatGPT, obawia się, że całkowicie zastąpi ono ich pracę.
Sztuczna inteligencja Google to nie wszystko. A właściwie firma Można powiedzieć, że za w wyścigu o sztuczną inteligencję. Ale jest niezaprzeczalnym faktem, że Google zatrudnia Niektórzy z najlepszych badaczy AI na świecie. A jeśli to najlepsze, na co mogą sobie pozwolić, to świadczy to o tym, że sztuczna inteligencja jest daleka od rozwiązania problemu.
Oto inne nagłówki AI zauważone w ciągu ostatnich kilku dni:
- Meta wprowadza generatywną sztuczną inteligencję do reklam: W tym tygodniu Meta ogłosiła pewnego rodzaju piaskownicę AI dla reklamodawców, aby pomóc im tworzyć alternatywne kopie, tworzyć tło za pomocą monitów tekstowych i przycinać obrazy do reklam na Facebooku lub Instagramie. Firma poinformowała, że funkcje są obecnie dostępne dla wybranych reklamodawców, a w lipcu rozszerzą zasięg na większą liczbę reklamodawców.
- Dodany kontekst: Anthropic rozszerzył okno kontekstowe dla Claude – swojego flagowego generowania tekstu i modelu AI, który jest wciąż w wersji zapoznawczej – z 9 000 tokenów do 100 000 tokenów. Okno kontekstu wskazuje, który tekst formularz bierze pod uwagę przed utworzeniem dodatkowego tekstu, podczas gdy tokeny reprezentują surowy tekst (np. „cool” zostanie podzielony na tokeny „fan”, „tas” i „tic”). W przeszłości, a nawet dzisiaj, słaba pamięć była przeszkodą w przydatności generowania tekstu dla sztucznej inteligencji. Ale większe okna kontekstowe mogą to zmienić.
- Antropia promuje „konstytucyjną sztuczną inteligencję”: Większe okna kontekstowe nie są jedynym czynnikiem różnicującym modele antropiczne. W tym tygodniu firma szczegółowo opisała „Constitutional AI”, swoje wewnętrzne podejście do szkolenia AI, które ma na celu nasycenie „wartości” w systemach AI „konstytucją”. W przeciwieństwie do innych podejść, Anthropic twierdzi, że konstytucyjna sztuczna inteligencja sprawia, że zachowanie systemów jest łatwiejsze do zrozumienia i łatwiejsze do modyfikowania w razie potrzeby.
- LLM ma na celu badanie: Non-profit Allen Institute for Artificial Intelligence Research (AI2) ogłosił, że planuje skoncentrowane na badaniach szkolenie LLM o nazwie Open Language Model, dodając do dużej i rosnącej biblioteki open source. AI2 postrzega Open Language Model, w skrócie OLMo, jako platformę, a nie tylko model — taką, która pozwoli społeczności badawczej wziąć każdy komponent tworzony przez AI2 i albo samodzielnie go używać, albo starać się go ulepszyć.
- Nowy fundusz AI: W innych wiadomościach AI2, AI2 Incubator, niedochodowy fundusz startowy AI, powrócił do trzykrotnej swojej poprzedniej wielkości — 30 milionów dolarów w porównaniu z 10 milionami dolarów. Od 2017 roku przez inkubator przeszło 21 firm, przyciągając kolejne inwestycje o wartości około 160 milionów dolarów i co najmniej jedno duże przejęcie: XNOR, akcelerator AI i urządzenie zwiększające wydajność, które Apple nabył później za około 200 milionów dolarów.
- Zasady wprowadzania UE dotyczące generatywnej sztucznej inteligencji: W serii głosowań w Parlamencie Europejskim w tym tygodniu posłowie do PE poparli szereg poprawek do projektu ustawy o sztucznej inteligencji – w tym ustalenie wymagań dotyczących tak zwanych modeli podstawowych, które stanowią podstawę generatywnych technologii sztucznej inteligencji, takich jak ChatGPT firmy OpenAI. Zmiany zobowiązały dostawców podstawowych modeli do wdrożenia kontroli bezpieczeństwa, środków zarządzania danymi i ograniczenia ryzyka przed wprowadzeniem swoich modeli na rynek.
- Tłumacz uniwersalny: Google testuje potężną nową usługę tłumaczeniową, która odtwarza wideo w nowym języku, jednocześnie synchronizując ruch ust mówiącego ze słowami, których nigdy nie wypowiedziała. Może to być bardzo przydatne z wielu powodów, ale firma otwarcie mówi o możliwości nadużyć i krokach, które podejmuje, aby temu zapobiec.
- Wyjaśnienia instrumentalne: Często mówi się, że LLM w stylu ChatGPT OpenAI jest czarną skrzynką i na pewno jest w tym trochę prawdy. Próbując odkleić swoje warstwy, OpenAI jest rozwijający się Narzędzie do automatycznego identyfikowania części LLM, które są odpowiedzialne za ich zachowania. Stojący za nim inżynierowie potwierdzają, że jest na wczesnym etapie, ale kod do jego uruchomienia jest dostępny jako open source na GitHub od tego tygodnia.
- IBM uruchamia nowe usługi AI: Na dorocznej konferencji Think IBM ogłosił IBM Watsonx, nową platformę, która zapewnia narzędzia do budowania modeli sztucznej inteligencji i zapewnia dostęp do gotowych modeli do tworzenia kodu komputerowego, skryptów i nie tylko. Firma twierdzi, że uruchomienie było spowodowane wyzwaniami, przed którymi wciąż stoi wiele firm we wdrażaniu sztucznej inteligencji w miejscu pracy.
inne uczenie maszynowe

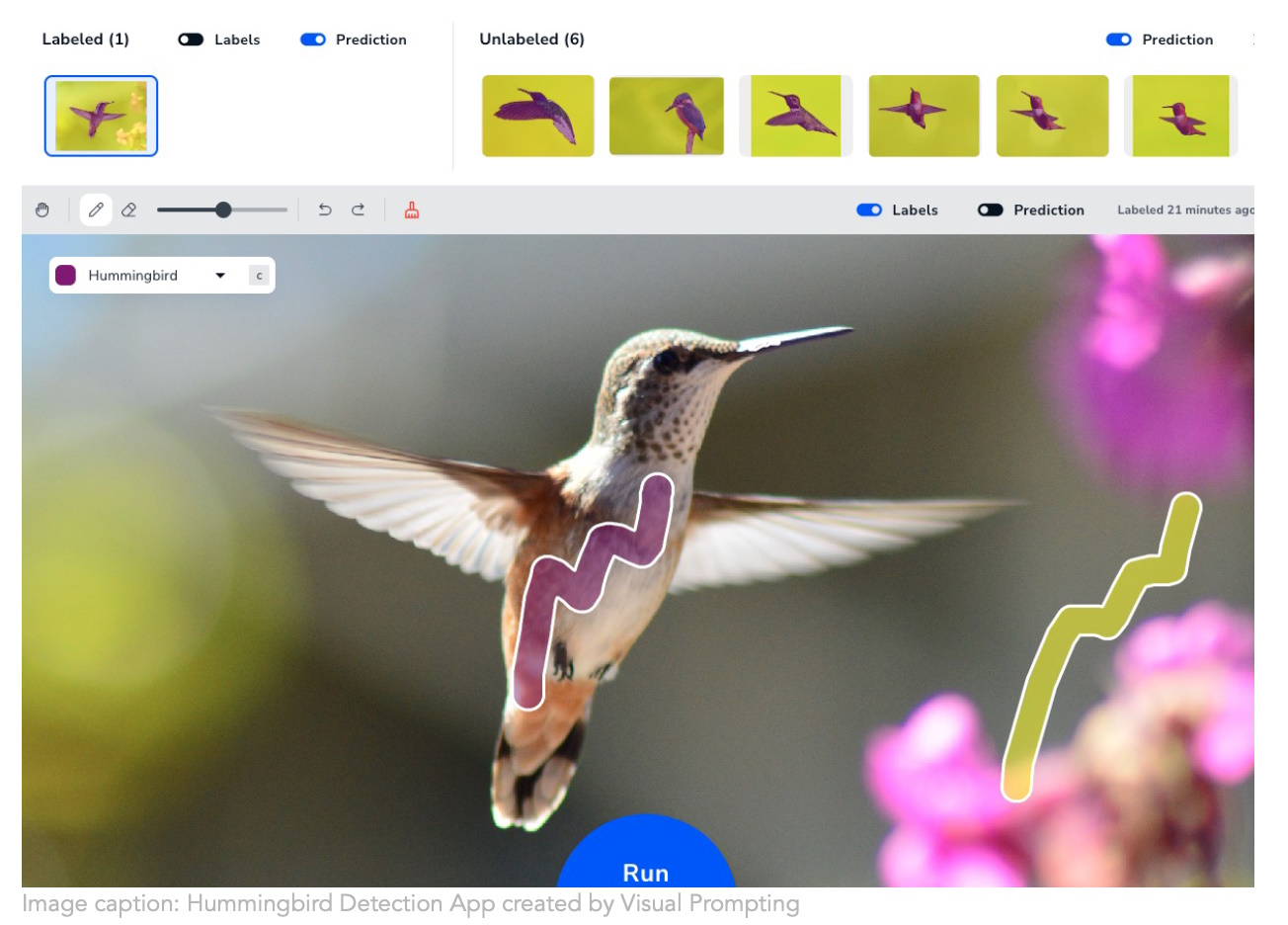
Kredyty obrazkowe: Upadająca sztuczna inteligencja
Nowa firma Andrew Ng Upadająca sztuczna inteligencja Przyjmuje bardziej intuicyjne podejście do tworzenia szkoleń z widzenia komputerowego. Tworzenie modelu, który rozumie, co chcesz zdefiniować na obrazach, jest jednak bardzo żmudne Ich technika „stymulacji wizualnej” Po prostu pozwala wykonać kilka pociągnięć pędzla i stamtąd określa intencję. Każdy, kto musi budować modele segmentacji, mówi: „O mój Boże, w końcu!” Prawdopodobnie jest wielu absolwentów, którzy obecnie spędzają godziny na ukrywaniu organelli i artykułów gospodarstwa domowego.
Microsoft wdrożył Modele dyfuzyjne w wyjątkowy i ciekawy sposób, zasadniczo używając ich do stworzenia wektora akcji zamiast obrazu, po przeszkoleniu w wielu obserwowanych ludzkich działaniach. To wciąż bardzo wczesne dni, a dyfuzja nie jest oczywistym rozwiązaniem tego problemu, ale ponieważ są one tak stabilne i wszechstronne, warto zobaczyć, jak można je zastosować poza zadaniami czysto wizualnymi. Ich artykuł zostanie zaprezentowany na ICLR jeszcze w tym roku.

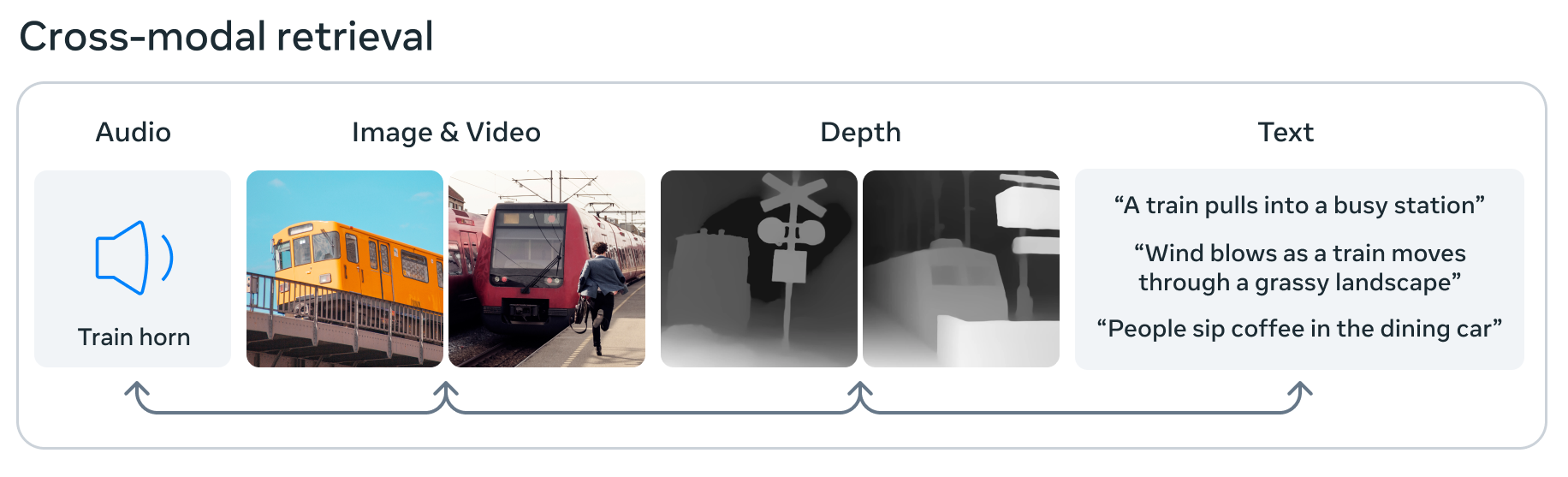
Kredyty obrazkowe: meta
Meta przesuwa również krawędzie sztucznej inteligencji ImageBind, który twierdzi, że jest pierwszym modelem, który może przetwarzać i łączyć dane z sześciu różnych metod: obrazów, wideo, audio, danych głębi 3D, informacji termicznych oraz danych dotyczących ruchu lub pozycji. Oznacza to, że w małej przestrzeni osadzania uczenia maszynowego obraz może być powiązany z dźwiękiem, kształtem 3D i różnymi opisami tekstowymi, z których każdy można odjąć lub wykorzystać do podjęcia decyzji. Jest to krok w kierunku „ogólnej” sztucznej inteligencji, ponieważ absorbuje i koreluje dane jak mózg – ale nadal jest prosty i eksperymentalny, więc nie ekscytuj się jeszcze.

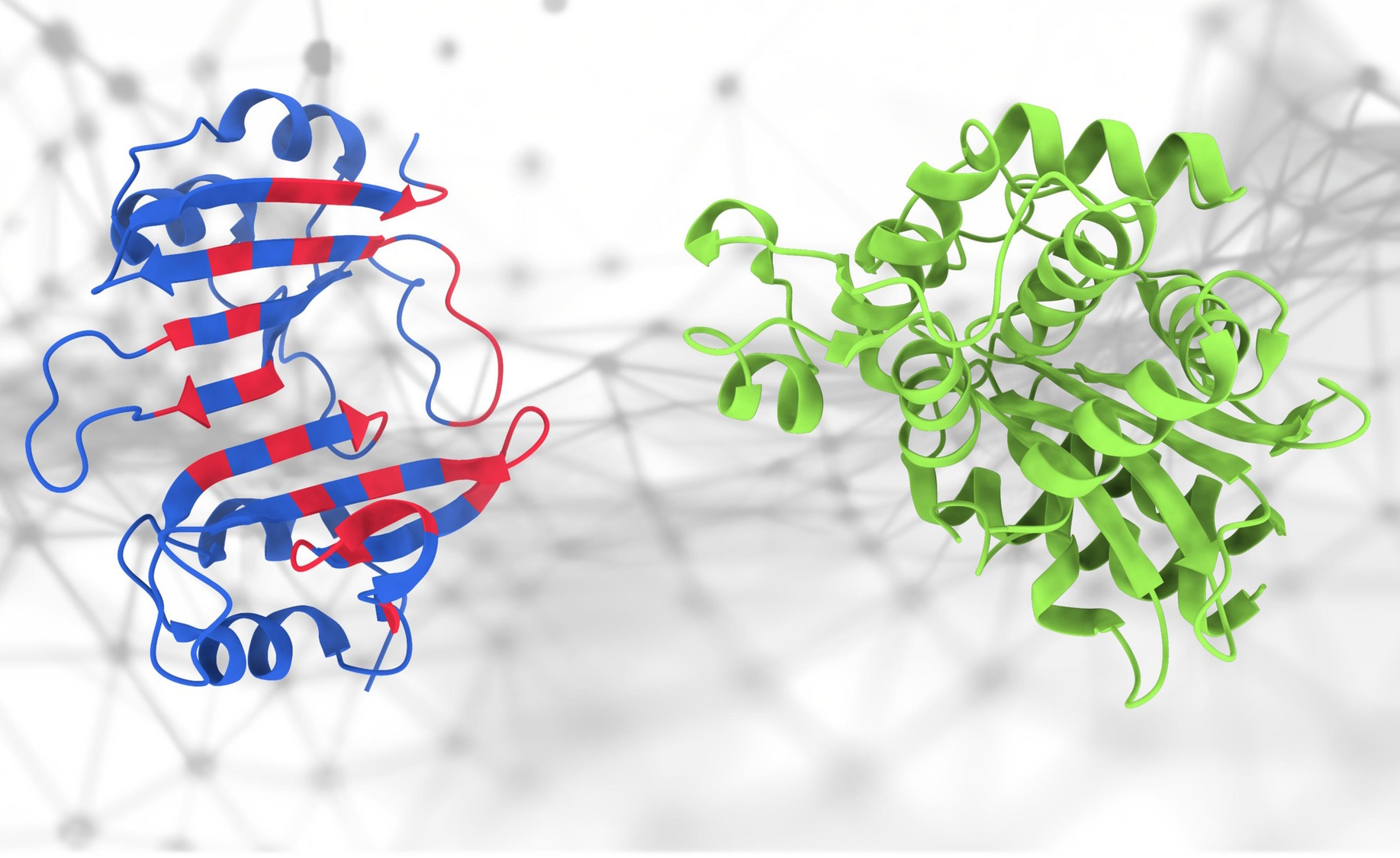
Jeśli dotkniesz tych białek… co się stanie?
Wszyscy byli podekscytowani AlphaFold i nie bez powodu, ale struktura to tak naprawdę tylko niewielka część bardzo złożonej nauki proteomiki. Sposób interakcji tych białek jest ważny i trudny do przewidzenia – ale to nowość Model PeSTO firmy EPFL Próbuje właśnie to zrobić. „Koncentruje się na ważnych atomach i interakcjach w strukturze białka” – powiedział główny programista Lucien Crabbe. „Oznacza to, że ta metoda skutecznie wychwytuje złożone interakcje w obrębie struktur białkowych, umożliwiając dokładne przewidywanie interfejsów wiążących białka”. Nawet jeśli nie jest w 100% dokładny lub niezawodny, brak konieczności rozpoczynania od zera jest niezwykle korzystny dla badaczy.
Federalni stawiają na sztuczną inteligencję. Szef nawet wpadł Poznaj grupę prezesów sztucznej inteligencji Aby pokazać, jak ważne jest, aby zrobić to dobrze. Być może grupa firm niekoniecznie będzie właściwą osobą, do której należy zapytać, ale przynajmniej będą miały kilka pomysłów wartych rozważenia. Ale oni już mają lobbystów, prawda?
Jestem bardziej podekscytowany Powstają nowe, finansowane ze środków federalnych, centra badań nad sztuczną inteligencją. Badania podstawowe są bardzo potrzebne, aby zrównoważyć pracę skoncentrowaną na produkcie, wykonywaną przez firmy takie jak OpenAI i Google – więc kiedy masz centra sztucznej inteligencji z uprawnieniami do badania rzeczy takich jak Nauki społeczne (na CMU)lub zmiana klimatu i rolnictwo (na Uniwersytecie Minnesoty), wygląda jak zielone pola (w przenośni i dosłownie). Chociaż chcę też trochę pokrzyczeć na ten temat Metawyszukiwanie miary leśnej.


Wspólne ćwiczenie AI na dużym ekranie – to nauka!
Dużo ciekawych rozmów o sztucznej inteligencji. wierzyłem Ten wywiad jest z naukowcami z UCLA (moja alma mater, Go Bruins), Jacobem Fosterem i Dannym Snelsonem To było bardzo interesujące. Oto świetny pomysł LLM, aby udawać, że przyszedłeś w ten weekend, kiedy ludzie mówią o sztucznej inteligencji:
Systemy te formalnie wykrywają spójność większości pism. Im bardziej ogólne formaty symulują te modele predykcyjne, tym większy jest ich sukces. Zmiany te skłaniają nas do poznania modułowych funkcji naszych form i możliwości ich transformacji. Po wprowadzeniu fotografii, która bardzo dobrze uchwyciła przestrzeń przedstawieniową, w środowisku malarstwa rozwinął się impresjonizm, styl, który całkowicie odrzucił dokładne odwzorowanie, aby pozostać przy materialności samej farby.
Zdecydowanie z tego korzysta!